开讲前我们先玩个猜谜游戏:
问题:猜一公司名字
线索1:这家公司与亚马逊、苹果和谷歌并称为全球四大科技公司。
线索2:这家公司创始于2004年。
线索3:截至2018年,该公司全球收入达558亿美元。
猜出这家公司应该是小菜一碟!(不过,我没有礼物给你)
答案:Facebook。
除了上述这些广为人知的信息,我还想带你看看几年前的Facebook,分享一些额外的小插曲。
2004年,马克·扎克伯格和四个哈佛大学的朋友共同创立了Facebook。两年过后,团队一直在竭尽全力地发展公司。2006年,扎克伯格聘请了首位数据科学家——杰夫·哈默巴赫,他是一位大学刚毕业的数学狂人。他在Facebook获得了一个令人尊敬的职位——研究科学家,主要负责研究人们如何使用社交网络服务。
在一次采访中,杰夫分享了在Facebook还没有相关工具时,他处理数据和构建新一类分析技术的经验。从Facebook离职后,他将自己所精通的数据科学拓展至其它领域,通过分析大型的生物数据集为癌症治疗提供更好的方案。
所有像杰夫这样的数据科学家,最终都把大量时间花在数据准备上,而不是把时间和技术知识只用到建模、计算和训练上。
为什么错误的数据会让你的分析城堡摇摇欲坠?
数据准备是一项乏味的工作。它需要花费大量的时间与精力,同时需要无误地进行创造性的探索。数据科学正朝着将数据应用于改善基础设施、交通、环境、医疗和许多其他重要领域的方向发展,以获得更好更高质量的生活。
接下来,本文将带你了解某些常见的数据准备错误,如错误的见解和策略、复杂模型的迭代以及分析模型的功能紊乱,这些错误都会让你付出巨大的代价、产生沉重的后果。
五个需要避免的数据准备大忌
1. 失去用例的情境-为什么偏离很危险
IT部门拥有的技术专长使数据准备的操作和实施成为可能。虽然IT部门和业务部门之间的这种控制的结合使业务知识与技术专业知识有机融合,但完全由IT部门负责的数据准备工作却有一个小小的弊端。

单纯由IT部门进行数据准备会缺少对于用例的商业理解,因此在进程中会失去情境。
若不考虑情境,公司则会花费大量金钱、时间和精力来准备数据,从而造成迭代周期重复和预期之外的输出级别。准确得知需求并对其有深入了解,这有助于企业将分析结果最大化,减少不必要的损失。
2. 忽略质量规则-脏数据等同于错误见解
准备数据时,对信息质量的关注至关重要。数据质量在B2B领域中颇受关注,许多数据质量问题亟待解决。那些数据可能是过时的、有缺失的、易出错的、不完整的等等。现在,如果数据质量低下,结论观点与分析也会很差。例如,假设我们正在为电子邮件营销活动准备营销数据。
假设一个重要的数据点,联系人的地理位置缺失(数据不完整的情况)。现在,当数据在没有纠正错误或增添信息的情况下,若其被进一步处理,会对输出产生巨大影响。这种情况下,只有添加联系人地理位置的相关数据,才能进一步增强并个性化营销活动消息。
3. 黄金法则:不要浪费数据科学家的时间,请聘请一个团队
数据科学家在分析、数据建模和设计程序方面的超强能力会为项目增添巨大价值。但从另一方面来看,数据工程师也会忙于提供干净、可用且经过良好处理的数据,这个过程通常被称为数据准备或数据整理。
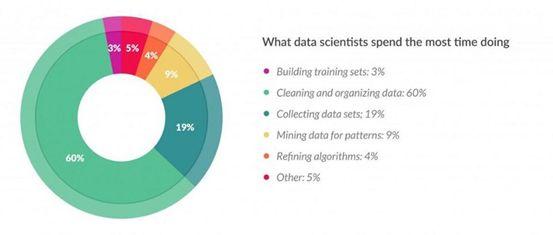
数据科学家80%的时间都花在数据准备上。他们作为将数据转化为观点的灵魂人物,还有谁能够替代他们呢?
作为数据管理员,数据科学家应有时间和空间把他们的知识用于更复杂的工作。但残酷而普遍的现实恰恰相反。这种做法的不利结果是,数据科学家一天中花在实际工作上的时间越来越少,也就延长了他们获得真知灼见和项目成果的时间。
这一问题如何解决呢?成百上千的数据准备服务供应商可以帮助处理进程,让数据科学家利用时间做他们该做的事情。
4. 如今是自动化时代,古老的手动方法需要逐步被淘汰
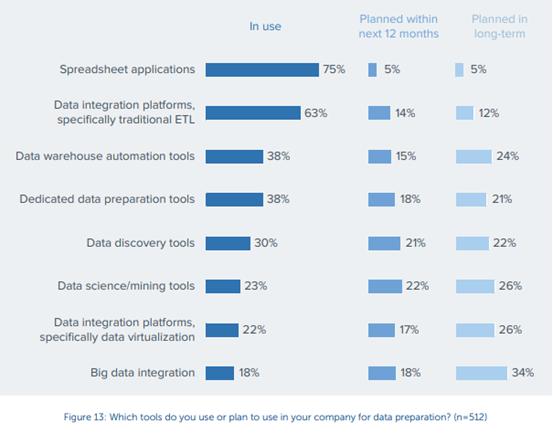
近期一项研究分享了有关公司数据准备工具的相关发现,结果令人震惊。电子表格应用程序高达75%,这表明,当前从数据中获得的分析范围和结论是受到了限制的,因为电子表格无法像自动化工具那样帮助数据转换和分析。复杂的自动化工具可以处理更多的数据,而电子表格基本无法支持数据准备功能。
由人工智能驱动的自动化数据准备过程将实现高质高效。数据准备不仅仅是数据的集成,还要将其转换为可分析的格式。自动化有助于数据质量问题的精准识别、数据的丰富、安全性的确保与数据沿袭。自动化应该取代电子表格来执行此类高级任务。
《机器学习的数据准备》一文将帮助你理解数据准备过程中不同步骤的本质。

5. 为什么需要用放大镜深入挖掘数据——命名惯例与人口规模问题
命名惯例必须设置得简单,因为在准备过程中要处理大量的数据。保持简单明了,便于分析人员理解。这些可以为整个组织全局设置,也可以专门为项目设置。
一个建模数据集至少应有1000条记录,至少保存三年,以保证排除范围或数据波动后得出的显著对比结果。更大的人口规模提供了更广泛和更深入的结论观点。
所以,你还有什么借口呢?
数据准备绝非一帆风顺。
无论是Facebook、亚马逊还是谷歌的数据科学家,没有坚实的基础,就无法建立自己梦想的分析城堡。对于一名数据科学家来说,他在一块巨大的白板上头脑风暴,讨论Linux集群和大量c代码,然而准备数据时发生的一个小小的错误就足以彻底消耗掉一切创新想法。
BARC的BI调查团队最近进行了一项研究,内容涉及当今数据准备的应用方式,需克服的挑战,以及使用的组织框架。其中有个有趣的发现,即公司在准备输出中有着糟糕结果的数据时所面临的问题类型。这些原因可能就是这些错误首次出现的原因。
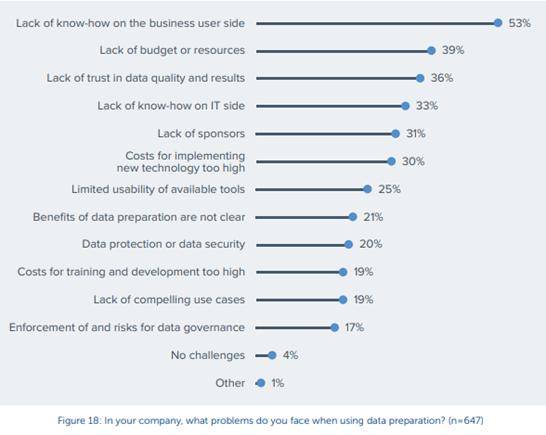
要避免这场致命祸患,运气或是不确定的修复方法没啥用。你所需要的是一套正确的预防措施,来彻底杜绝此类情况的发生;你所需的是援助之手以及准备准确数据集时的适量专业知识。
这才是你所需要和应该准备的。